
內容目錄
前言
在 上一篇文章 裡,我們介紹了Python Pandas厲害的地方
本篇文章則是要分享
如何使用 Python Pandas 來抓取在 【台灣證券交易所】 揭示的每日股價資訊
並在使用 Pandas 存成 Dataframe 後
存到 SQLite3 這個資料庫內,以利後續分析
結構
主要可以分成
第一洞: 找到資料來源
這邊會以 【台灣證券交易所】 為例
第二洞: 將資料抓下來並解析成 Pandas 可讀的格式
Pandas 是啥? 請見下個段落
第三洞: 使用 Pandas 存成 Dataframe
存了之後試試看可否做簡單的資料篩選
第四洞: 將資料分存入 SQLite3 內
這樣子之後我們就可以使用存在SQLite3 裡面的資料來做下一步處理了
預備知識
在實作前有些名詞須要先了解一下
所以簡單列一下會用到的名字解釋
Pandas
可以想像成是 Windows 的 excel
用途是快速地對資料做運算並整理成一張張厲害的表格
requests
Python 常用的 package
它可以將網路上的資料給下載下來,給程式使用
.csv檔
.csv是一種檔案的格式
它可以被excel或記事本打開 (對!就是 windows 的那個記事本)
實作
第一洞: 找到資料來源
可以點開台灣證券交易所的網站如下
https://www.twse.com.tw/zh/
step 1
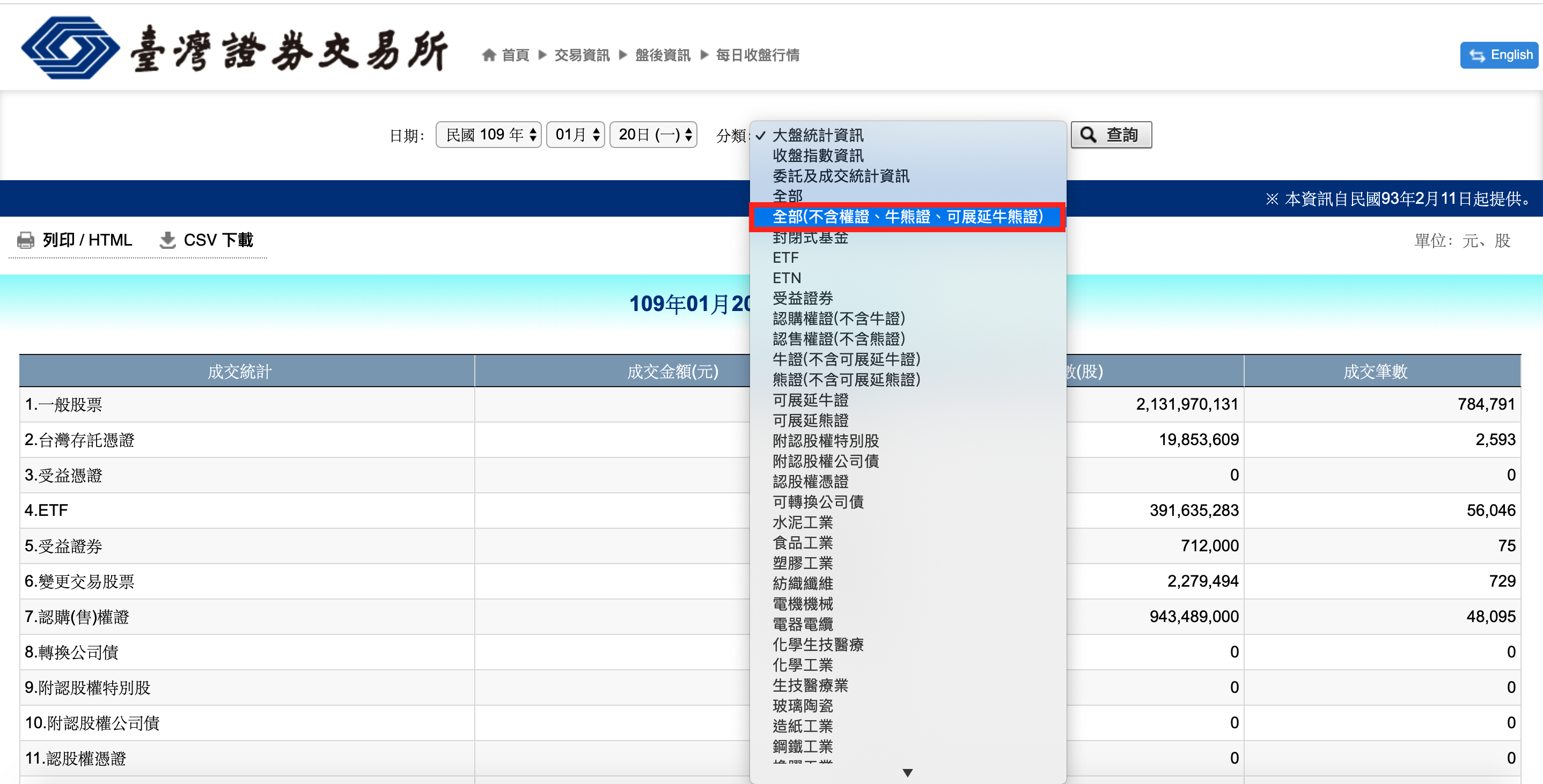
點選【交易資訊】裡的【每日收盤行情】

step 2
在【分類】裡點選【全部(不含權證…)】
並按下查詢
step 3
打開「開發者工具」 (以下以Chrome為例)
- 在網頁任一處點右鍵->檢查即可
step 4
點開【Network】分頁,這邊可以看到你在操作網頁時與server互動的情況
請點選【CSV下載】
此時你可以看到右邊開發者工具多了很東西
請點選MI_INDEX?開頭的那個 就可看到右邊有一個 Request URL
這個就是你點了【CSV下載】後會發出去的 request
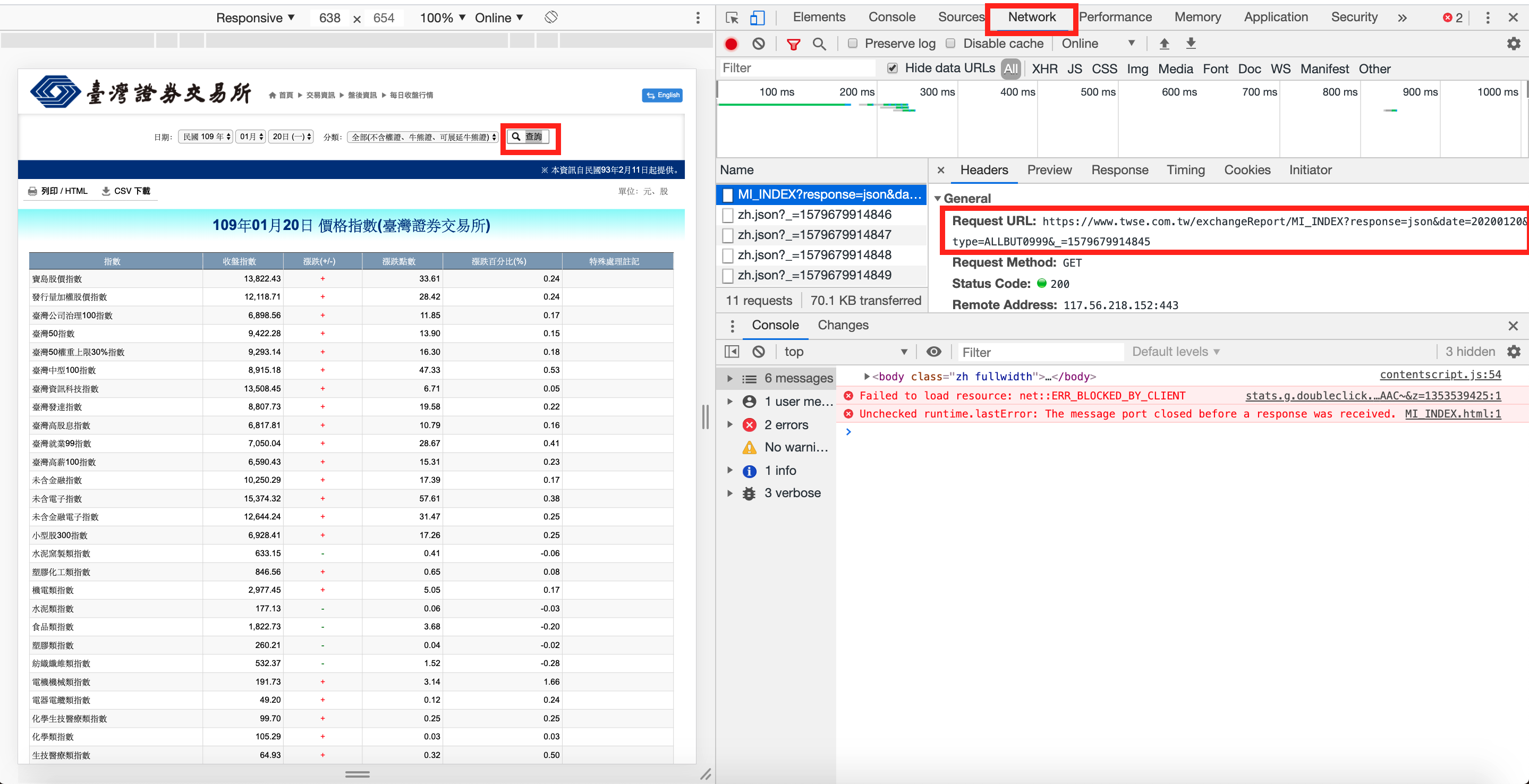
這個 request 會回傳【每日收盤行情】的資訊回來
接著我們就是要利用這個 request 來拉股市資訊下來處理
step 5
將這個 URL 複製下來貼到網址列裡
https://www.twse.com.tw/exchangeReport/MI_INDEX?response=csv&date=20200120&type=ALLBUT0999
你會得到以下畫面
這樣就可以把股市資訊的
csv檔給抓下來了而其中的
【date=20200120】就是你要抓的資料日期而這也意謂著
我們可以用這個 URL 來抓任意日期的股市資訊了
第二洞: 將資料抓下來並解析成 Pandas 可讀的格式
ps. 【貼心提示】以下內容請搭配 code 傳送門服用
https://github.com/BenmrChen/Python/blob/master/Stock_data.ipynb
step 1
使用以下程式碼來使用python把資料抓下來
並存到 response 這個變數裡
import requests
import pandas as pd
from io import StringIO
response = requests.get('http://www.twse.com.tw/exchangeReport/MI_INDEX?response=csv&date=20200120&type=ALLBUT0999&_=1520785530355')step 2
試試可這個抓下來的資料可否用
pandas直接存取
lines = pd.read_csv(StringIO(response.text))結果報錯了,它說:
ParserError: Error tokenizing data. C error: Expected 7 fields in line 193, saw 17意思是在193行,程式預期有7個欄位
但實際上有17個欄位
程式就卡住報錯了
怎麼辦呢?
這時候我們可以打開剛剛下載下來的.csv檔
這才發現
原來是因為檔案的上半部和下半部的欄位不一樣多
以致會有 pandas 讀不出來的情形發生
所以接下來就是要處理一下資料
才能讓 pandas 好處理囉~
step 3
我們使用split這個 function 來為.csv檔分行(.csv是用'\n'來斷行的)
並一行一行存到lines變數裡
然後把第100行印出來看看是啥
lines = response.text.split('\n')
print(lines[100])
print(lines[200])嗯看起來符合預期 讚!
而且我們要的資料是下面那筆 總共有17個欄位的
所以要處理的就是把不要的那個給拿掉
step 4
我們使用
",這個符號再把剛剛存在line這個變數的字串給拆開由於我們只要有17個欄位的資料
所以寫一個判斷
把有17個欄位的存到
newlines變數裡並簡單驗證一下
原來的
lines變數內的資料筆數和新的newlines變數內的資料筆數是否有變更
newlines = []
for line in lines:
if len(line.split('",')) == 17:
newlines.append(line)
print(len(lines))
print(len(newlines))step 5
接著把剛剛的
newlines給印出來看看
print(newlines)看起來是我們想要的東西沒錯!
step 6
現在的狀況是
我們有一個list,裡面有超多筆data
但為了要讓 pandas 解析
所以我們必須要讓它成為一個string
所以使用以下 code
將
newlines變數給黏起來並印出來看看它有多長(string長度)
也印出來看看內容對不對
最後再用
type函式來確認是不是string
s = '\r'.join(newlines)
print(s)
type(s)好的! 這樣子看起來就差不多了
我們可以開始準備用 pandas 來解析囉
第三洞: 使用 Pandas 存成 Dataframe

第四洞: 將資料分存入 SQLite3 內

完成!