情境
假設現在我們有一個情境要生成 500 個 SQL
UPDATE `tableA` INNER JOIN `tableB` ON `tableA`.`foreign_id` = `tableB`.`id` SET `setting_value` = "number:111" WHERE `tableB`.`test_name` = "testABC";其中
裡面的變數 111 和 testABC
然後我們有一個 excel 的 mapping table 長的像這樣
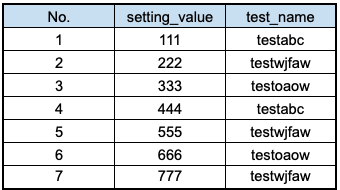
裡面就記載了這 500 句 sql 組成的邏輯
現在是還簡單 基本上是一對一的關係
也就是:
111 會對應到 testABC
222 會對應到 testwjfaw
原則上還是可以用 excel 內建的公式來建
但如果複雜一點
比如說根據條件 A ,來決定 111 要對應到的是 testABC 還是 testwjfaw
這樣就會有點複雜
雖然應該還是可以用 excel 的公司來寫 但就會有點麻煩
以下我們就來看看要怎麼用 python 完成吧!
步驟
step 1
首先將 excel 輸出成
csv 檔當作是 python 要引入的資料源
step 2
新增 createSQL.py 檔
並在裡面把我們要批次更新的 sql 寫成類變數的型式
temp_sql = 'UPDATE `tableA` INNER JOIN `tableB` ON `tableA`.`foreign_id` = `tableB`.`id` SET `setting_value` = "{setting_value}" WHERE `tableB`.`test_name` = "{test_name}";'step 3
引入剛剛下載下來的
csv 檔並使用 replace function 來替換掉要改的變數
with open('/your-path-to-file/testFile.csv') as csvfile: # 打開 csv
rows = csv.reader(csvfile, ) # 將 csv 內容一行一行存到 rows
next(rows);
for row in rows: # 一列一列更新
print (temp_sql.replace('{setting_value}','{number' + row[2] + '}').replace('{prod_level2_oid}',row[3])) # row[2]代表第二欄 、row[3]代表第三欄step 4
執行 python
直接在 command line 裡
python ./createSQL就可以把 sql 都 print 出來了!
結語
最後附上 github 連結: https://github.com/BenmrChen/createSQL.py/blob/main/createSQL.py
有問題的歡迎大大們留言討論
謝謝!